Introduction
Skin conditions, particularly skin lesions, are common and often difficult to diagnose due to their visual similarity. This solution focuses on leveraging deep learning and image processing techniques to improve the classification of skin lesions using images captured by mobile phone cameras. The main goal is to process and enhance these images before feeding them into a deep learning model for classification.
Image Processing in Skin Lesion Classification
Dataset Preprocessing
The dataset used in this project (HAM10000 dataset), contains images of various skin lesions. The dataset is imbalanced, Data Augmentation was performed to ensure the model generalizes well. The list of data augmentation steps applied to the dataset includes:
- Horizontal and vertical flipping
- Rotation by 45 degrees
- Image translation
- Scaling
This project was performed using 2 CNN models namely AlexnNet and MobileNet
AlexNet Architecture
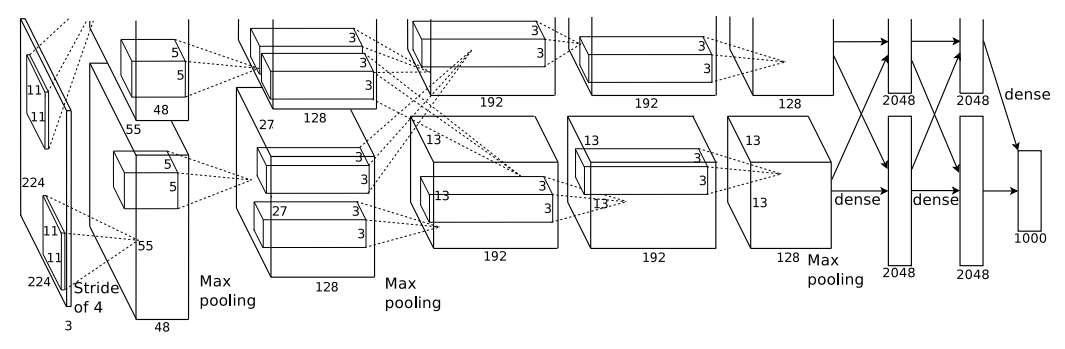
AlexNet is a deep convolutional neural network (CNN) that revolutionized computer vision when it won the ImageNet competition in 2012.
It consists of eight layers: five convolutional layers followed by three fully connected layers. The network processes input images of size 224×224×3 (RGB)
MobileNet-v2 Architecture
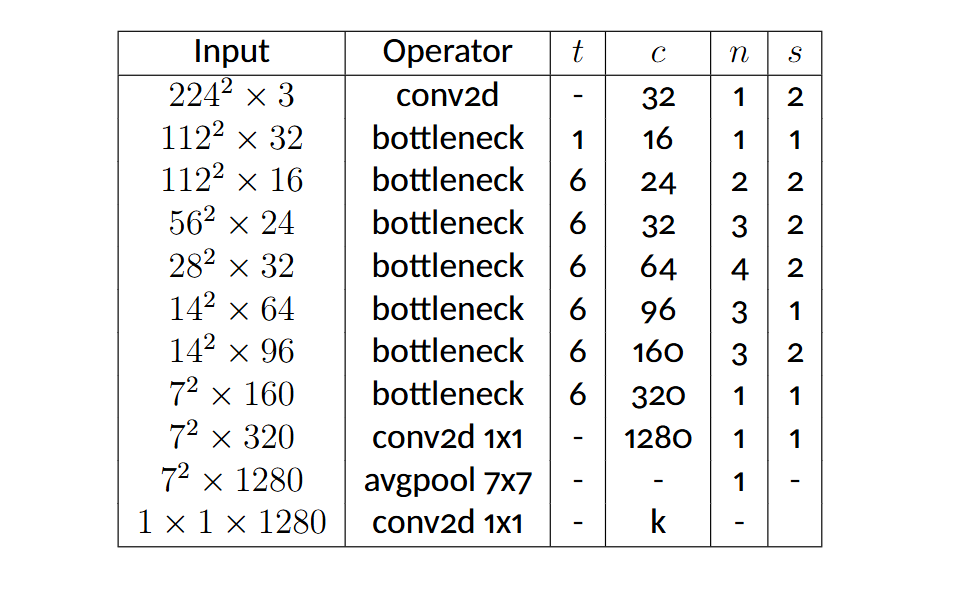
MobileNetV2 is an efficient deep learning model designed for mobile and embedded devices, offering a good balance between accuracy and computational cost.
The MobileNetV2 architecture begins with a standard convolutional layer, followed by multiple bottleneck residual blocks that implement the inverted residual and linear bottleneck concepts
Deep Learning Model Integration
This part was completed using the Python programming language. The CNN models and relevant functions were loaded using the PyTorch framework. The following are the primary code snippets of the steps in this section:
Importing Necessary Packages
import torch
import torch . nn as nn
import torch.nn.functional as F
from torchvision import datasets , transforms , models from torch.utils.data import random_split ,DataLoader ,WeightedRandomSampler
import json
import numpy as np
from sklearn.metrics import confusion_matrix , accuracy_score,precision_score , recall_score , classification_report
import matplotlib . pyplot as plt
import seaborn as snsSplitting the Data and Preprocessing the Images
Training data was selected as 80 % of the whole dataset. Test data accounted for 20% of the whole dataset. The random split function was used to divide the dataset randomly while keeping specified proportions
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms, models
from torch.utils.data import random_split, DataLoader, WeightedRandomSampler
import json
import numpy as np
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, classification_report
import matplotlib.pyplot as plt
import seaborn as snsImplementing the weighted Random Sampling method to handle class imbalance
Weights were chosen to balance sample probabilities across classes. This prevents the over-representation of specific classes.
train_targets = torch.tensor([all_data.targets[i] for i in train_data.indices])
class_counts = torch.bincount(train_targets, minlength=7)
for class_id, count in enumerate(class_counts):
print(f'Class {class_id} count: {count.item()}')
weight= 1./class_counts
train_size = int(0.8 * len(all_data))
test_size = len(all_data) - train_size
train_data, test_data = random_split(all_data, [train_size, test_size])
# Set transformations
train_data.dataset.transform = train_transform
test_data.dataset.transform = test_transform
print(len(all_data.targets))Model Setup
Weights were chosen to balance sample probabilities across classes. This prevents the over-representation of specific classes.
number_of_classes = 7
model = models.alexnet(pretrained=True)
# model= models.mobilenet_v2(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.classifier = nn.Sequential(
nn.Linear(9216, 1024),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(1024, number_of_classes),
nn.LogSoftmax(dim=1)
).cuda()
model.cuda()Training loop
The loss was calculated using the cross-entropy loss criterion, and the weights were adjusted using the Adam optimizer with a learning rate of 0.001.
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.001)
num_epochs = 100
train_losses = []
test_losses = []
train_acc = []
test_acc = []
all_train_true_labels = []
all_train_pred_labels = []
all_test_true_labels = []
all_test_pred_labels = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct_train = 0
total_train = 0
epoch_train_true_labels = []
epoch_train_pred_labels = []
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
correct_train += (predicted == labels).sum().item()
total_train += labels.size(0)
epoch_train_true_labels.extend(labels.cpu().numpy())
epoch_train_pred_labels.extend(predicted.cpu().numpy())
all_train_true_labels.extend(epoch_train_true_labels)
all_train_pred_labels.extend(epoch_train_pred_labels)
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = 100 * correct_train / total_train
train_losses.append(epoch_loss)
train_acc.append(epoch_acc)
model.eval()
test_loss = 0.0
correct_test = 0
total_test = 0
epoch_test_true_labels = []
epoch_test_pred_labels = []
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
correct_test += (predicted == labels).sum().item()
total_test += labels.size(0)
epoch_test_true_labels.extend(labels.cpu().numpy())
epoch_test_pred_labels.extend(predicted.cpu().numpy())
all_test_true_labels.extend(epoch_test_true_labels)
all_test_pred_labels.extend(epoch_test_pred_labels)
test_losses.append(test_loss / len(test_loader.dataset))
test_acc.append(100 * correct_test / total_test)
print(f"Epoch [{epoch + 1}/{num_epochs}], "
f"Train Loss: {epoch_loss:.4f}, Train Acc: {epoch_acc:.2f}%, "
f"Test Loss: {test_losses[-1]:.4f}, Test Acc: {test_acc[-1]:.2f}%")Evaluation
Following training, the results were reviewed with the following code:
accuracy = accuracy_score(test_true_labels, test_pred_labels)
precision = precision_score(test_true_labels, test_pred_labels, average='weighted')
recall = recall_score(test_true_labels, test_pred_labels, average='weighted')
print(f"Accuracy: {accuracy * 100:.2f}%")
print(f"Precision: {precision * 100:.2f}%")
print(f"Recall: {recall * 100:.2f}%")
print(classification_report(test_true_labels, test_pred_labels))
conf_matrix = confusion_matrix(test_true_labels, test_pred_labels)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.title('Confusion Matrix')
plt.show()Results and Impact of Image Processing
The project successfully developed a skin lesion classification system using CNN models. A web application was created to enable user interaction with the classifiers. While promising, additional metadata such as age, gender, and lesion location could improve classification accuracy.
- MobileNet-V2 achieved an overall accuracy of 88.93% across all 7 classes.
- Binary classification tasks achieved an average accuracy of 97%, demonstrating the effectiveness of preprocessing techniques.